We pitted 23 LLMs against each other on a real production task
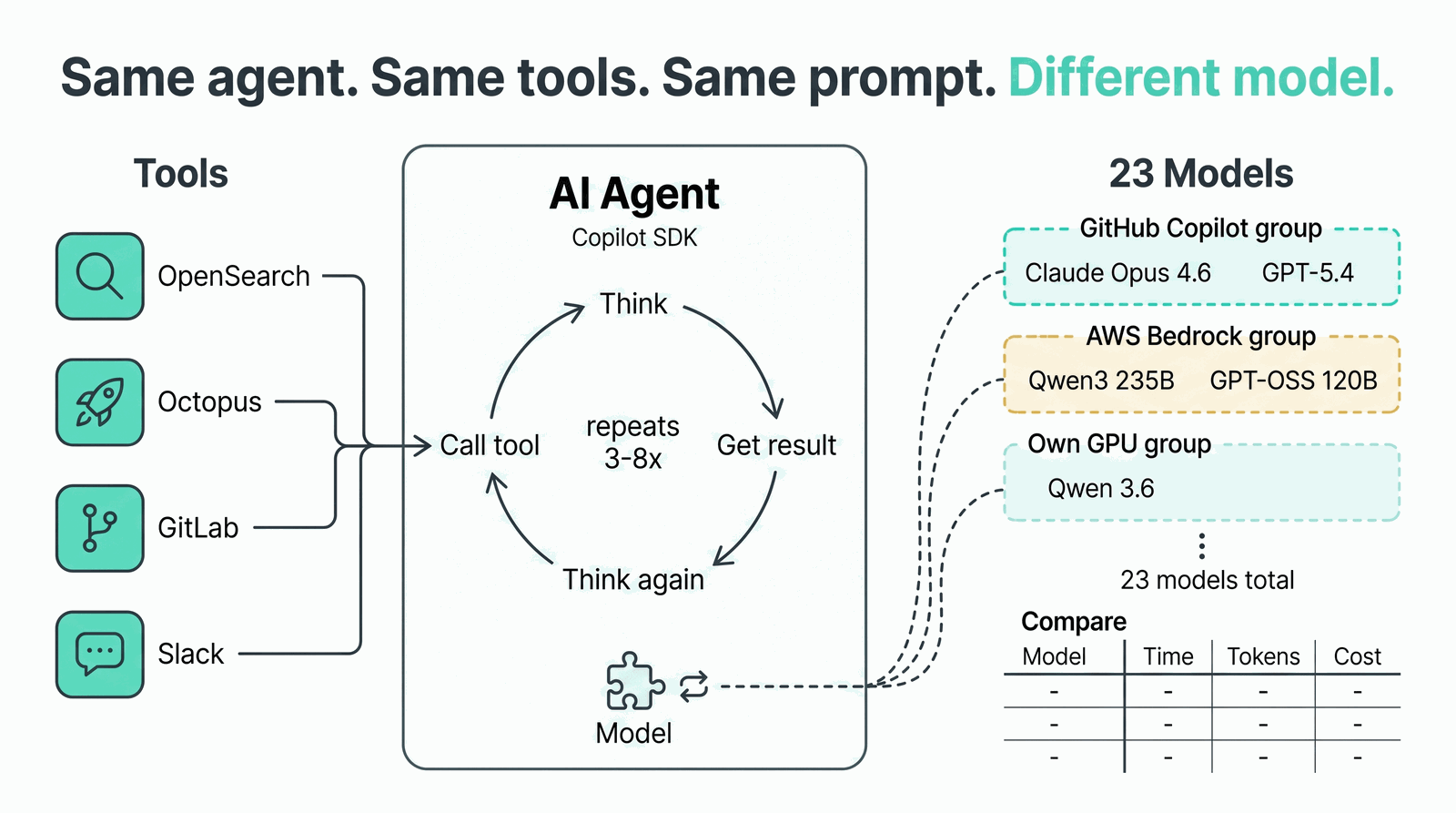
At RiksTV, we have an AI agent that monitors production deployments. It’s wired into OpenSearch, Octopus Deploy, GitLab, and Slack, all through tool-calling in an agentic loop.
Each deploy triggers multiple checks: log analysis, error detection, performance comparison against the previous version. And not just once: the agent re-runs at widening intervals afterward to catch errors that take time to appear. Some days we deploy a handful of times, other days it’s dozens. When we ran it all on Claude Sonnet, the bill passed $100/day and we started asking: does it have to be Sonnet?
The agent is built on the Copilot SDK, which means swapping models is a config change. We route through three providers: GitHub Copilot gives us Claude and GPT-5.x. AWS Bedrock gives us open models like Qwen and GPT-OSS. And we had access to an Nvidia Spark GPU, running Qwen 3.6 via Ollama.
Same agent, same tools, same prompt. 23 models. One question: who does the job for the least money?
How we test
We built the evaluation harness into the application itself. No separate test suite, no mock tools. The eval mode uses the exact same agent loop, system prompt, and CLI tools as production. The only variable is the model.
dotnet run -- --eval \
--prompt "What are the top 5 exceptions the last week?" \
--json output/eval-results.jsonEach model gets the prompt, reasons about it, calls tools to query real systems, feeds the results back, and keeps going until it has an answer. We measure time taken, token consumption, tool calls, and cost. All models run in parallel so the whole thing finishes in minutes.
The example above asks about exceptions, and that’s deliberate: digging through logs to find the errors that matter is the bulk of what the agent does on each deploy. It’s the most demanding part, so it’s the fairest way to tell models apart.
The cost formula is simple: (input tokens / 1M * input price) + (output tokens / 1M * output price). Every model has its pricing declared in config so the numbers are apples-to-apples.
Here’s the full picture: same prompt, same tools, all 23 models in parallel.
What one investigation costs
The same question, answered correctly by every model here, costs anywhere from nothing to over a dollar. Sorted by cost:
| Model | Backend | Time | Tokens (in/out) | Tools | Cost |
|---|---|---|---|---|---|
| Qwen 3.6 | Own GPU | 330s | 1.1M / 7.9K | 46 | $0.00 |
| Qwen3 Coder 30B | Bedrock | 10s | 62K / 0.4K | 3 | $0.01 |
| Qwen3 235B | Bedrock | 21s | 72K / 0.4K | 5 | $0.02 |
| GPT-OSS 120B | Bedrock | 215s | 397K / 9.6K | 22 | $0.07 |
| GPT-5.3 Codex | Copilot | 124s | 143K / 3.7K | 11 | $0.30 |
| Claude Sonnet 4.6 | Copilot | 80s | 152K / 2.9K | 8 | $0.50 |
| GPT-5.4 | Copilot | 109s | 207K / 4.5K | 17 | $0.59 |
| Claude Opus 4.6 | Copilot | 96s | 214K / 3.2K | 11 | $1.15 |
The spread is the story. Claude Opus costs 115x more than Qwen3 Coder 30B on Bedrock, and 16x more than GPT-OSS 120B. Same answer, very different bill.
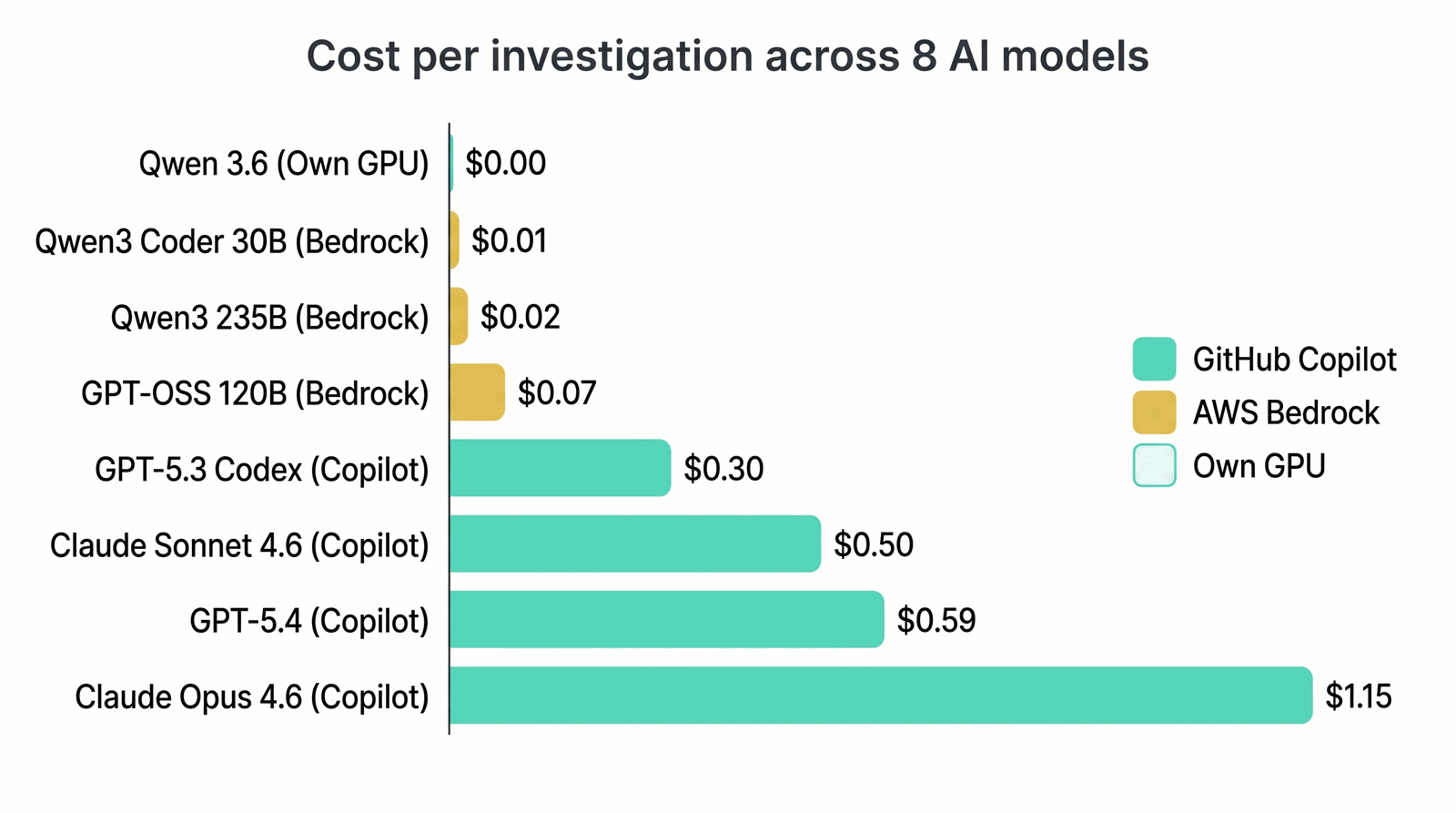
But the line worth staring at is the $0.00 one. Qwen 3.6 runs on our own Nvidia Spark GPU via Ollama. It’s much slower than the API-hosted models and works harder to get there, with more tool calls and more tokens. But it produces correct answers and costs nothing per run. For a system running dozens of analyses per day, that adds up fast.
Some models can’t do this
Not every model handled the agentic loop.
Nemotron Nano 30B ate 2.68M input tokens, looping the same log query over and over without making progress. Tool use is often binary. A model either gets it or it doesn’t.
Magistral Small went the opposite way: 9 seconds, zero tool calls, one-line answer based on training data. Technically fast and nearly free. Also useless.
Devstral 2 123B and Nemotron Super 120B never made it past the first API call. We marked them “Broken” after repeated failures.

What we learned
Build for evaluation
The eval harness took a few hours to build. It reuses the exact same production agent loop, just adds metrics collection and a parallel runner. The one design decision that made this possible: the model is a config parameter, not a hardcoded string.
Every time a new model appears on Bedrock or Copilot, we add one line to the config and run --eval. Five minutes later we know if it’s worth switching.
Evaluate features, not the whole application
The agent does several things: deploy analysis, alert investigation, ad-hoc Q&A, and rollback execution. Each has different requirements.
Deploy analysis benefits from a model that reasons carefully over log data. Rollback execution is mostly calling one tool with the right arguments. A $0.01 model handles rollbacks fine. Deploy analysis is harder, but cheaper models like Qwen and GPT-OSS can do it well with more precise instructions. We’re now moving toward mixing models per feature: cheap where cheap works, a stronger model only where it earns its place.
Own hardware is a real option
The self-hosted Qwen worked well. The question was whether it would be too slow to be useful. It wasn’t. It completed every evaluation prompt, produced correct answers, and cost nothing per run.
The tradeoff is speed, not cost. Our Spark is slower than Bedrock or Copilot API calls. For background tasks like scheduled deploy analysis, that doesn’t matter. For interactive queries where someone is waiting in Slack, we would still route to a faster model.
Token efficiency matters as much as price
Qwen3 Coder 30B used 62K input tokens to answer the same question that Nemotron Nano 30B burned 2.68M on. The cheapest model per token isn’t the cheapest model per task.
Some models are chatty. They call more tools than necessary and burn through tokens on long reasoning chains. Others go straight for the answer. A cheap price per token doesn’t help if the model uses 10x more of them.
When this isn’t worth it
If your LLM costs are a rounding error in your cloud bill, a 23-model eval is over-engineering. Same if you only have one or two prompts and latency matters more than cost. Just pick a frontier model and move on.
That said, this wasn’t a big investment. We vibe coded the evaluation harness and used Opus to score the answers, then spot-checked the top performers manually to make sure they were actually correct. The whole thing took a few hours and is trivial to re-run. For us, $100/day on a single agent made it obvious we should look at alternatives. At $5/day, we probably wouldn’t have bothered.
Does it have to be Claude?
No. But the answer to “which model instead?” changes every month. The eval harness matters more than any single result in the table above. It’s the thing that lets us ask the question again next time a new model drops.