Stop losing information; Event Sourcing
The feeling of losing data on a daily basis is not a good feeling. Nor is the lack of understanding the code of your system, what changes can be made to it and how the processes are. Often hidden away in hard-to-understand data or object models, because of this, these challenges are exactly what event sourcing aims to solve.

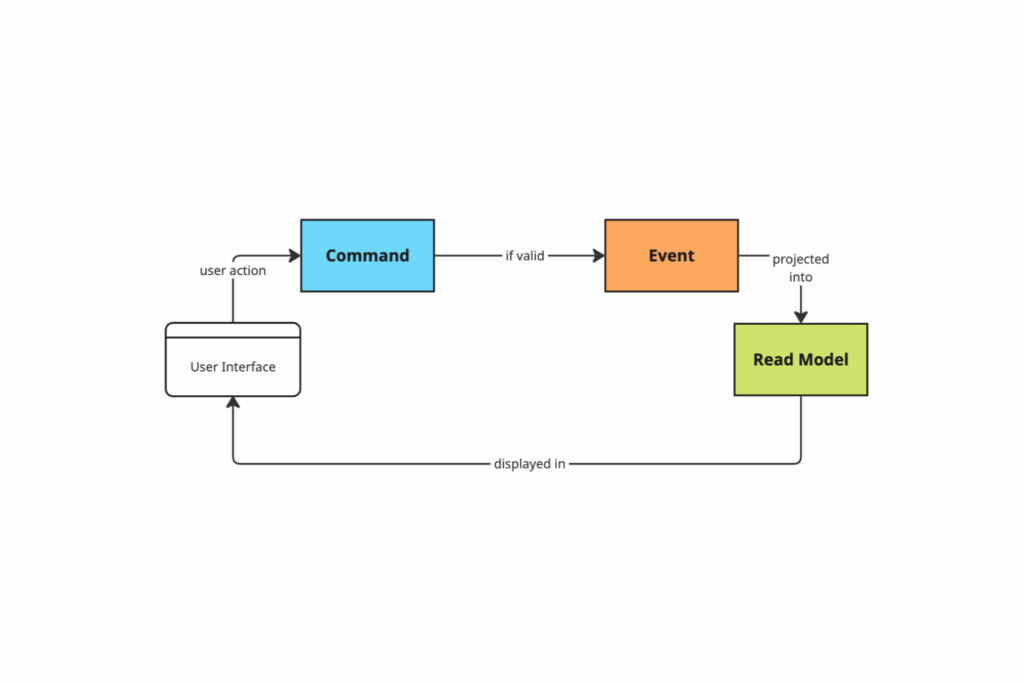
That’s really the starting point for the biggest difference between a traditional database-oriented (CRUD) architecture and an event sourced one. Where a traditional architecture gives you the system’s current state, on the other hand, event sourcing gives you all the clues to how that state came to be. These clues are reflected in the events produced at runtime and the event types modeled in the code that lead to meaningful state-changes.
Another aspect is how we design the systems we build. In addition to traditional modeling approaches, there are techniques like Event Modeling that capture a timeline of the system. This kind of modeling is meant to be collaborative and used to capture domain language and processes. It’s intended as a living document that everyone on the team relates to.
All in all, event sourcing adds information, both to the running software and to the code. Consequently, this leads to more insight and improved decision-making.
What is event sourcing?
In a traditional database-centric architecture, you model tables or documents. These have various properties in the form of columns or attributes. They’re the system’s source of truth, often representing abstractions of the real world and reused across different parts of the business. In other words, they typically represent the nouns of your system: employee, customer, product, etc.
With event sourcing, that’s flipped on its head—you go after the verbs, the meaningful changes in the system. Verbs are a more natural way of thinking for the business. Typically one focuses on processes and they have natural transitions when we perform actions; verbs.
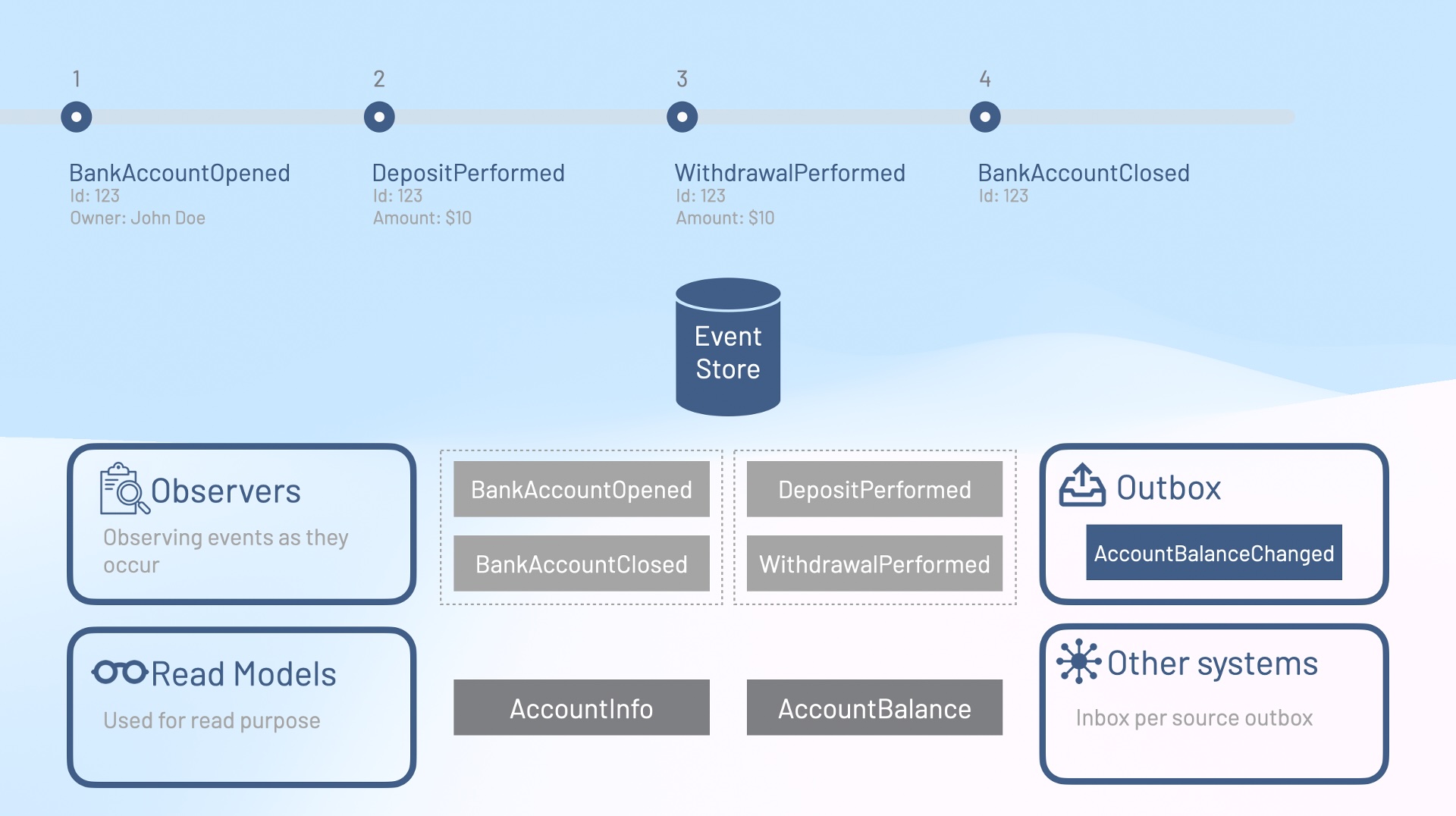
Take eCommerce as an example. Instead of a database with tables representing shopping carts and their contents, you’d have events like:
- CartCreated
- ItemAddedToCart
- QuantityChangedForItemInCart
- ItemRemovedFromCart
With this, you now have much more information to go on. You get insight into what users are doing and can optimize the store accordingly. In a traditional database, you would typically just see the end state; the cart. You would not capture vital information about what was for instance removed, which could prove very valuable for the business to know. You would simply have to retrofit this data, while with event sourcing, you just get it «for free».
These changes—events—usually have clear, descriptive names that indicate what changed. They only represent the change itself and carry the values that changed. That is now your new source of truth.
From these events, you can build snapshots that represent a point-in-time view of the system. That’s an optimization you can do depending on the use case, but you don’t have to. You can also replay the events to recreate state. Again, this depends on the use case.
It’s important not to mistake event sourcing with event-driven. Event-driven usually refers to a system that reacts to events, whereas event sourcing is much more strategic and stores absolutely everything that happens in the system and treats that as the source of truth. These events should never be deleted.
Why Event Sourcing?
We always have to Start with Why as Simon Sinek says. We’ve discussed the most important one; stop losing information, there are more. With every event we have provided full traceability. By adding metadata about who or what system made the change and when, you’ve got yourself a perfect audit trail. A good example could be a patient journal where you want to know exactly who did what & when. This is very often the case for line of business software.
The perfect audit trail could also be leveraged to be displayed to the end user. Instead of showing what field was changed at what time, you can actually show the intent and specific event that caused it – providing the user with more information to understand exactly what has happened and empower them in their decision making.
Software comes with bugs or problems and it can be hard to reproduce issues being reported, even if you have logging or other metrics and traces. With event sourcing, you can rewind the system to any point in time. That’s a powerful tool for developers when debugging.
One of the biggest advantages of event sourcing is letting each feature in your system leverage events in its own way. You can build state views tailored to specific use cases, using the tech best suited for the job. Example: product registration events in an eCommerce platform can be used to build a product catalog stored in a document database, while another system might use the same events to keep a search index in sync.
These same events can also be used in an event-driven style—triggering actions like sending emails, texts, or talking to other systems.
Having the events gives you choices to build out and scale out in a different way both organizational and technical.
Event Sourcing, Modularization and Microservices
Many want to modularize their systems and go full microservices to get modular deployments. A big driver here is loose coupling. To get that right, you really need to use Bounded Contexts from Domain-Driven Design.
Think of it as boundaries that can deliver business value independently. Back to eCommerce—warehouse and storefront are two separate contexts. They both deal with “product,” but they care about entirely different aspects of it.
In the warehouse, it’s about boxes, dimensions, weight, and location. In the store, it’s about category, brand, price, etc. The store only cares about available inventory, which can be communicated via events from the warehouse to the store.
A common event sourcing pattern here is the outbox/inbox pattern. Events go into an outbox, and other microservices pick them up into their inboxes.
This leads to much looser coupling. Many teams have built microservices but ended up with tight coupling by calling APIs directly. That increases complexity and makes failure scenarios harder to handle. Using events between well-bounded services helps you get to the actual goal: independently deployable, loosely coupled services.
What About Performance and Scalability
Event sourcing (and event-driven architecture) is often associated with scalability and performance. And there are benefits that can be leveraged.
For instance, being able to optimize and pick the correct storage for each scenario in a solution. Use a relational database for reporting, documents for the core application and search indexes for your search capabilities.
When scaling out you don’t want to expose your internal events. Instead you create public events that contain enough information without an external consumer having to piece together to get to accurate world view. It’s all about conscious ownership and ends up making it more maintainable and easier to scale with less friction.
But don’t lose track and get sucked into a technical problem looking for a solution. Remember the bigger benefits of not losing information and the fact that this info never disappears.
Long-term Flexibility
One big benefit is future-proofing. By breaking down state into individual changes, you make it easy to build new features on top. Add a new feature tomorrow? You can replay all historical events to generate whatever new view or model you need. Done right and you have linear scale.
Challenges and Pitfalls
The biggest hurdle? Existing knowledge.
If your team is used to working the “traditional way,” event sourcing is a 180-degree shift. You have to unlearn. Developers need to understand the value and potential of event sourcing—it’s not just a new way to store stuff, it’s a new mindset. The mindset shift is both on how you model your system and technical implementation. There are ways of thinking about concurrency boundaries and consistency models that gives you more flexibility and makes for more conscious decisions.
Obviously there are new things to learn; tools, mindset, modeling. Keep this in mind if considering event sourcing. It’ll be totally worth it, but you have to plan for this.
One more thing: systems evolve. So will your events do. You may want to rename them, add new fields, split them, or drop them. Like database schema migrations—but on a lower level. You need a strategy and hopefully tool support for that. However, for the most part you will most likely just be adding new event types, as they represent new knowledge in your domain. With more fine grained (atomic) events, you more seldomly need to change existing. But it can happen.
When Should You Consider Event Sourcing?
Of course; Always, as a good Sith Lord would say 😊 Perhaps a better answer being a little bit less in absolutes; “It depends.” For a basic website, probably not—unless you need traceability. A better answer might be: consider it for your core domain, the heart of your business. But if your domain is simple and static, it might not be worth it.
Event sourcing is rooted in Domain Events, as described in Eric Evans’ Domain-Driven Design. If you’re building a system with a rich domain, meaningful state transitions, and clear processes—then you should seriously consider event sourcing.
Audit trails, scalability, and flexibility are great bonuses—but to me, the real reason is modeling your domain better and getting tighter control of your system’s flows.
Tools and Ecosystem
Some folks in the event sourcing community say “you don’t need tools—just build it yourself.” That’s easy to say if you’ve been doing this for a decade. If you’re new, I’d recommend using tools.
The most well-known event store is KurrentDB (formerly EventStoreDB). It’s been around for years and is laser-focused, like SQL Server or MongoDB—but just for events. It’s commercial.
In the .NET world, Eventuous builds on KurrentDB, and MartenDB is probably the most popular—it’s a library on top of PostgreSQL.
I also develop and maintain an open-source project: Cratis, a more holistic stack; library, and tooling on top, built on top of existing database technologies such as MongoDB and soon any relational SQL DB.
Think through your needs. If you plan to replay events to generate new data views—that’s doable with all of them, but usually requires code. If that’s not important to you, most tools have feature parity. It really depends on what level you want to operate on. And what developer experience you’re looking for.
How To Get Started
Depends a bit on where you want to begin. Martin Fowler’s site is always a good place for pattern definitions—you’ll find a good write-up there. Eric Evans’ Domain-Driven Design is still the go-to for managing complexity and understanding domain events.
There is also a specific book on Event Sourcing called «Understanding EventSourcing» by Martin Dilger which I recommend.
For technology choices, there are a couple of options out there:
- KurrentDB
- MartenDB
- Cratis Chronicle (open source project I’m working on)
- EventSourcingDB
I’ve worked with event sourcing for the last 15-16 years on different solutions leveraging Cratis Chronicle and previous incarnations. You typically see me doing talks on the subject at conferences or communities. The talk I gave at NNUG is a solid starting point—you’ll find it on YouTube. We at Novanet can help you get started with Event Sourcing and Event Modeling.