Slik løste vi NM i AI
Forrige helg stilte Novanet for første gang i NM i AI. Tre utviklere, 69 timer, tre helt forskjellige oppgaver. Det var intensivt, lærerikt og veldig, veldig gøy! Årets lag har laget en oppsummering fra helgens store begivenhet.

Hva er NM i AI?
NM i AI er en nasjonal konkurranse og satsning for å fremme AI-kompetanse i Norge. I årets utgave deltok 3 234 personer fordelt på nesten 500 lag, med en premiepott på én million kroner.
Konkurransen besto av tre ulike oppgaver:
- En AI-regnskapsagent (Tripletex)
- En prediksjonsmodell for en norrøn sivilisasjonssimulator (AStar Island)
- Objektdeteksjon av dagligvarer på butikkhyller (NorgesGruppen Data)
Totalscoren var gjennomsnittet av alle tre. Bare seks lag klarte å plassere seg i topp 50 på alle tre oppgavene. For å gjøre det bra totalt måtte man altså mestre bredden.
Teamet
Vi stilte med Hallstein Brøtan, Jan Tore Hageskal og Jan Ødegård, og ingen hadde tidligere erfaring fra slike konkurranser. Det vi derimot har er erfaring med å bygge AI-drevne løsninger i det daglige, en god porsjon nysgjerrighet og intens lakenskrekk. Helgen før NM lekte vi oss med oppvarmingsoppgaven, Grocery bot. Der erfarte vi raskt at det lønner seg å ha en strategi (skriftlig) på plass før man gyver løs på oppgavene.
Tre oppgaver, tre ulike tilnærminger
Selve konkurransen besto av tre helt ulike oppgaver, som hver for seg krevde tre ulike tilnærminger.
Vikingsimulatoren, maskinlæring mot det ukjente
Astar Island var oppgaven der vi kanskje var mest kreative. En norrøn verden simuleres i 50 år hvor bosetninger vokser, fraksjoner kriger, skoger brer seg over ruiner og alt styres av skjulte parametere vi ikke kjenner. Vi fikk observere verden gjennom et begrenset 15×15-vindu på et 40×40-kart, med bare 50 spørringer per runde fordelt på fem tilfeldige starttilstander. Utfordringen var å predikere sannsynlighetsfordelingen for hele kartet basert på disse smale glimtene.

Hvordan vi løste oppgaven
Her kommer en beskrivelse vi ikke hadde skjønt opp ned på for en uke siden:
Vi bygget en progressiv modellarkitektur som utviklet seg gjennom konkurransen. Fra en statistisk grunnlinje (transisjonsmatriser) via gradient boosting med romlige naboskapsfeatures og nevrale nett trenet med KL-divergens som tapsfunksjon, endte vi med et U-Net, altså et convolutional nettverk som ser hele kartet som et bilde og lærer romlige mønstre direkte. Bayesiansk oppdatering basert på observasjonene kalibrerte prediksjonene per runde.
En nøkkeldisiplin var LORO-validering (Leave-One-Round-Out), hvor ingen modellendring slapp gjennom til produksjon uten å bevise at den ville ha fungert på historiske runder. Over 22 runder utviklet vi ti modellversjoner uten en eneste regresjon helt til vi brøt vår egen regel én gang, med påfølgende nyttig læring.
Her skal det sies at Opus 4.6 var essensiell hjelp, og det ble mange prompts av typen «Hvordan kan vi forbedre scoren vår?», «Hva er topp 3 prioriteringer den neste timen?», «Er du sikker på at vi ikke kan gjøre dette på en bedre måte?».
Viktig lærdom
Logg alle forespørsler og svar fra serveren. Her trengte vi all data for å kunne trene opp modellen. Med totalt 23 runder var det tynt treningsgrunnlag, så det var viktig å få med alle rundene (vi gikk glipp av fire totalt på grunn av sen oppstart og tekniske problemer underveis).
Resultat
23. plass av 395 lag. Vår beste råscore (84.9) var høyere enn vinnerlagets (84.3). Beste rundeplassering var vi på 8.plass.
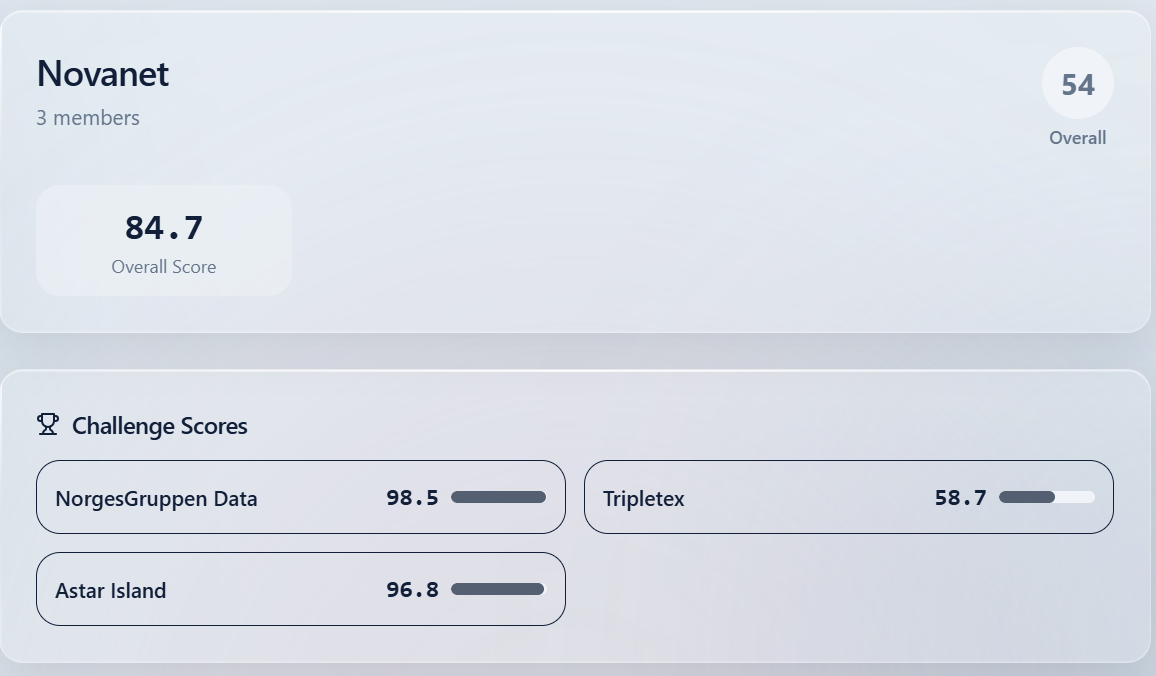
Relativ score på 96.8%, så denne oppgaven ble en suksess!
Fun fact
Det kom nye kart hver tredje time, så Hallstein måtte ha nattevakt og alarm på telefonen for å stå opp og trene modellen for å levere på det nye kartet. Vi prøvde å automatisere dette, men det krasjet på første forsøk, så da ble det manuell oppfølging for å være sikker.
Dagligvaredeteksjon, modelltrening ftw!
For NorgesGruppen Data skulle vi finne og klassifisere dagligvarer på bilder av butikkhyller med opptil 235 produkter per bilde, fordelt på 356 kategorier, mange med kun én eller to treningseksempler.

Hvordan vi løste oppgaven
Vi startet med det vi trodde var den elegante løsningen med en to-stegs pipeline der YOLO finner produktene og et separat embedding-nettverk klassifiserer dem ved å sammenlikne mot referansebilder. Etter fem timers arbeid toppet denne tilnærmingen ut på 0.23. Så kom vendepunktet hvor vi gikk over til en ren YOLO-modell trent i 100 epoker som scoret 0.69, altså nesten tre ganger bedre.
Derfra bygget vi et multiskala-ensemble med flere YOLO-modeller i ulike størrelser (medium, large, extra-large), kjørte på flere oppløsninger (1280 til 2240 piksler), fusjonert med Weighted Box Fusion. Vi utnyttet Google Cloud for å trene modeller parallelt på GPU-er med opptil åtte(!) samtidige treningsjobber. En automatisert kombinasjonssøker evaluerte alle gyldige modellkombinasjoner fra forhåndsberegnet cache på sekunder.
Viktig lærdom
Vi startet med å trene modellene lokalt, men høye GPU-krav gjorde at PC-en krasjet brutalt og det var fare for brann. Vi hadde også problemer med minnelekasjer i starten. Dette dyttet også heldigvis i riktig retning, nemlig å sette opp VM-er i Google Cloud som tok seg av modelltreningen. Vi burde dog satset mer på diversifisering av modellene og overfitting.
Resultat
Her var det veldig jevnt, og mange som klarte en høy relativ score.
Vi endte på relativ score på 98.5%, så denne oppgaven ble også en suksess!
Fun fact
Det ble totalt brukt $185 000 på Google Cloud denne helgen og de lagene som brukte mest var på $24 000 hver. Vi var ikke i nærheten av det.
Regnskapsagenten, frustrerende og lærerikt
Tripletex-oppgaven var den mest kodeintensive med en AI-agent som mottar regnskapsoppgaver i naturlig språk på norsk, engelsk, spansk, portugisisk, nynorsk, tysk eller fransk, og som deretter gjennomfører dem via Tripletex’ API.
Hvordan løste vi oppgaven
Vi bygde en tre-stegs pipeline med GPT-4o som tolket oppgaveteksten og trakk ut strukturert JSON, en router sender dette til riktig handler, og 20+ spesialiserte klasser gjennomfører selve API-kallene. For oppgaver uten dedikert håndtering hadde vi en fallbackagent som brukte GPT-4o i en loop for å finne riktig kombinasjon av API-kall på egen hånd.
Viktig lærdom
Arkitekturen fungerte godt for enkle oppgaver, vi matchet lederen på 11 av 30 oppgavetyper, og ledet på én (reiseregning). Den hadde dog en stor svakhet; promptet vokste til 5000 tokens og ble stadig mer uforutsigbart, og hver kodeendring krevde rekompilering. I ettertid ser vi at domenekunnskap burde ha ligget i filer (skills), ikke i kompilert kode. Det ville ha kuttet iterasjonstiden fra minutter til sekunder. Vi både kunne og burde gått for en større modell (Sonnet 4.6 eller Opus 4.6), all den tid kostnad ikke var en dimensjon å ta hensyn.
Resultat
Vi fikk 58.7% relativ score og endte på 118. plass på oppgaven, men lærte samtidig kanskje også mest av denne. Hadde vi bare fått levert ferdig det vi gjorde på søndag så hadde vi trolig fått en mye høyere score her.
Fun fact
Ikke så «fun», men arrangøren hadde tekniske problemer som gjorde at vi ikke fikk sendt inn mye av det vi hadde gjort på søndag, og gikk dermed glipp av mange poeng på denne oppgaven. Det gjaldt selvfølgelig flere. Arrangøren valgte likevel å ha med denne oppgaven med 1/3 vekting på totalscoren.
AI-verktøy som lagkamerat
En rød tråd gjennom hele konkurransen var bruken av GitHub Copilot i agentmodus med Opus 4.6 som LLM. Copilot implementerte modellversjoner fra konseptuelle beskrivelser, debugget feil, bygget analyseskript, og vedlikeholdt en levende kunnskapsbase der alle funn, feil og overraskelser ble logget i sanntid.
Vi ga Copilot detaljert kontekst om kodebasen, API-konvensjoner og arbeidsflyt. Den viktigste lærdommen var at verktøyet trenger mer enn teknisk kontekst, det trenger strategisk kontekst. Scoringregler, prioriteringsmatriser, eksplisitte regler for å stoppe og spørre istedenfor å bare kode videre. Uten slike rekkverk ble Copilot en ekstremt effektiv implementerer av det vi ba om, men ikke alltid av det vi burde ha bedt om. I fremtidige konkurranser vil vi gi AI-assistenten enda mer domenekunnskap om selve spillet, ikke bare om koden som skal produseres.
Resultatet
Vi la til sammen ned over 150 timer med arbeid gjennom helgen. Vi endte på 54. plass totalt av nesten 500 lag med en totalscore på 84.7 poeng, 13.3 poeng bak vinnerne Ave Christus Rex, som tok hjem førsteplassen med 98.0
poeng.
Dessverre opplevde arrangøren ytelsesproblemer på Triplextex-oppgaven, og i praksis ble innleveringen sperret de siste to timene før frist. Dette var frustrerende for oss som hadde jobbet tre mann hele søndagen uten å få poeng på det vi hadde gjort.
Fasiten viser at:
- Vi slo vinnerlaget på to av tre oppgaver.
- Hvis man fjerner Tripletex-oppgaven hadde vi kommet på 8.plass.
Gapet var altså ikke kompetanse, det var strategisk fokus, iterasjonshastighet og kontinerlig læring, selv når mangelen på søvn gjorde hodet tungt.
Dette er oppløftende, og gir oss motivasjon til neste års konkurranse!
Hva lærte vi?
Konkurranser er gøy!
Helgen ble fryktelig intensiv, med minimalt antall timer søvn og trolig altfor mye koffein. Å dykke dypt ned i problemstillinger gir en helt egen tilfredsstillelse når man lykkes med å løse dem. Vi skal ikke legge skjul på at vi kjente på abstinenser søndag ettermiddag etter at laptopen var lukket. Vi hadde vært 69 timer i Narnia og kom ut igjen fra klesskapet og tilbake i den virkelig verden.
Fokus krever tid og rom
Vi satt i samme rom kun fredag kveld, men erfarte at vi nok burde tatt fredag fri fra jobb og f.eks. leid en hytte sammen, slik at kommunikasjon og fokus hadde fungert enda bedre.
Bredde slår dybde
Vi visste dette på forhånd og skrev det i strategidokumentet vi laget før konkurransen startet. Likevel perfeksjonerte vi det som nesten fungerte, istedenfor å sikre minimumsscore på alt.
Iterasjonshastighet er alt
I en 69-timers konkurranse teller hvert minutt. Å flytte domenekunnskap fra kode til konfigurasjonsfiler ville nok ha spart oss noen timer.
Strukturerte pauser lønner seg
Vi manglet faste retrospektiver underveis. En 15-minutters gjennomgang med «jobber vi med det mest verdifulle nå?» ville ha fanget opp de største strategiske feilene i tide.
Veien videre
Vi stiller igjen! Med grundige post mortems for alle tre oppgaver har vi nå et detaljert kart over hvor vi kan forbedre oss på alt fra arkitekturvalg til prompting-strategi og hvordan vi instruerer AI-assistenter under tidspress. NM i AI var en intens, lærerik og vanvittig morsom opplevelse, og vi gleder oss til neste runde.
Kontakt
Vil du vite mer om hvordan du kan bruke AI og agenter til å forbedre dine produkter eller prosesser?